

Introduction
If you are a software vendor in the SaaS business or running mission-critical applications within your organization, one of the biggest challenges is providing software updates without downtime. There are several well-known techniques to achieve this goal. Which one is going to be applied, as usual, depends on a use case. Another thing to consider is how to automate this process? Manual deployments are error-prone. Humans make mistakes, while machines if configured correctly, do this process flawlessly.
This article will talk about CodeDeploy, a managed service from AWS that allows us to automate deployments to physical instances, virtual machines, containers, and Lambda functions. As the title suggests, we will focus on serverless, which means Lambda.
Before we dive into the CodeDeploy and actual implementation, let's talk about few essential multi-purpose concepts.
Common Types of Deployments
The most common deployment strategies are:
- Blue/Green
- Linear
- In place
- All at once
- Canary
Of course, this is not written in stone. There are variations and combinations of these strategies that DevOps engineers apply according to their requirements.
What is deployment strategy anyway? The answer is straightforward, but the implementation is not always simple. Deployment strategy is how our application will be replaced with the new version.
If we take the Blue/Green strategy as an example, there is a running environment with the current version in production (Blue). In contrast, the new version is installed and tested in a completely isolated environment (Green). Once we feel confident that the latest version is ready, we switch traffic from Blue to Green.
We can leave the old Blue environment running for some time if something goes wrong to switch back. If all goes well, we can shut down the Blue environment, and then our Green environment has officially become Blue. This process is perpetual.
Canary and Linear Deployments
Gradual deployment is a variation of the Blue/Green deployment strategy previously described. In this strategy, we still have two environments while the traffic shifting is happening in phases. These phases can be defined as a step or linear.
Canary traffic shifting implies that traffic from Blue to Green will be shifted in two steps. To make this more understandable, we can decide to divert 10% of traffic to the Green environment while maintaining 90% of traffic to the current version. If something goes wrong, we roll back traffic to the Blue environment. Otherwise, if we are confident that the new version is running smoothly, we switch the rest of the traffic to the Green environment.
On the other hand, Linear strategy is where we switch a specific percentage of traffic per amount of time. For example, we can define that traffic will redirect by 10% every 10 minutes from Blue to Green. This way, we are gradually deploying a new version of software to our users. That's all the theory we need. How can we do that in practice?
Lambda Versioning
Let's now make a slight drift to a different topic closely related to what we are trying to achieve. When deploying a Lambda function on each new deployment a unique version for that function is created. The version number is associated automatically.
As we all know, almost everything on AWS is a resource. Each resource on AWS has a unique Amazon Resource Number (ARN). However, Lambda has two types of ARN, "Qualified" and "Unqualified".
Unqualified ARN is just a regular ARN that we can use to invoke our function. When we use unqualified ARN, we are referencing the latest version.
Example of unqualified ARN:
*arn:aws:lambda:us-west-2:123456789012:function:photo-prod-get-file*
The example above will target the latest version of the lambda function.
Qualified ARN allows us to target the specific version of the function by using version suffix on the ARN. An important note about versioning is once we publish a new version, it becomes locked. We cannot change it anymore for consistency reasons. If we want to change something, the only way to do it is to publish a new version.
Example of qualified ARN:
*arn:aws:lambda:us-west-2:123456789012:function:photo-prod-get-file:23*
The example above will target version number 23 of the lambda function.
Now we know that we can maintain different versions of the function, the question that remains unanswered is how can we make use of it?
Lambda Aliases
One of Lambda's most valuable and underestimated features is the possibility to add an alias to the function versions. It is important to understand that the Lambda function can be invoked by using either function name, qualified ARN, unqualified ARN, or function alias. Once created, an alias gets its own ARN. Here is the CLI example:
aws lambda invoke --function-name FUNCTION_UNQUALIFIED_ARN:alias-name output
Why is giving the name to our function version so important? Let's consider the use case where we are making event source mapping between DynamoDB stream and Lambda. The usual procedure is to map function ARN or name with the event source ARN. When we do this, our mapping is always targeting the latest Lambda version.
aws lambda create-event-source-mapping \
--function-name photo-prod-get-file \
--batch-size 100 --starting-position LATEST \
--event-source-arn STREAM_ARN
The obvious downside of this is the fact that our Lambda will evolve at some point. We will either make some improvements or do a bug fix. Once we do that, we have to deploy a new version, and if all goes well, we are good. What happens if we introduce a new bug? The consequences can be a total failure of our service and unexpected downtime. We have to revert our function to the previous version or fix an error then deploy the new version. During that time, our application in production is not working. Saying it simply, we are in big trouble.
A much better and desirable approach is to create and map function alias. Our mapping will always target an alias. What we are going to change on new deployments is the version to which the alias is pointing. So our mapping should look like this:
aws lambda create-event-source-mapping \
--function-name FUNCTION_UNQUALIFIED_ARN:alias-name \
--batch-size 100 --starting-position LATEST \
--event-source-arn STREAM_ARN
We haven't mentioned that an alias can point to two versions, where one version is the so-called "weighted alias." By using the alias, we can split traffic.
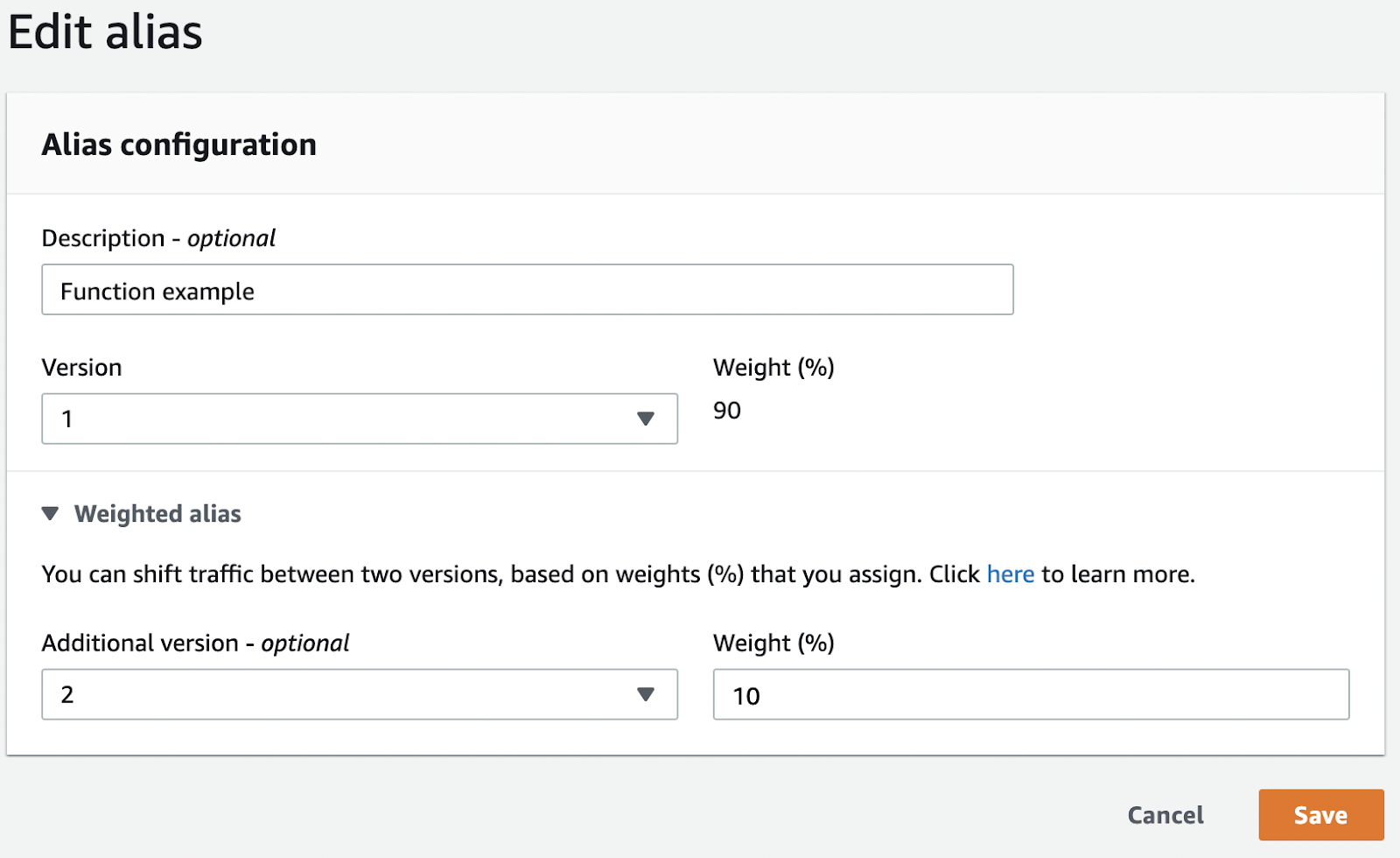
With this approach, we can make use of the benefits that gradual deployments provide. We can revert the entire traffic to the previous version if something goes wrong. The production show continues without service interruptions. If there are no issues, we can gradually increase traffic percentage to the new version until we reach 100%.
This juggling can be done using the console, CLI, or SDK. So far, we did everything manually. How can we automate this process?
CodeDeploy
It's worth mentioning that all of these steps can be done using Infrastructure as Code, which is a recommended approach. In our first example, we will use the AWS console.
Deployment
Let's create a CodeDeploy application and deployment group.
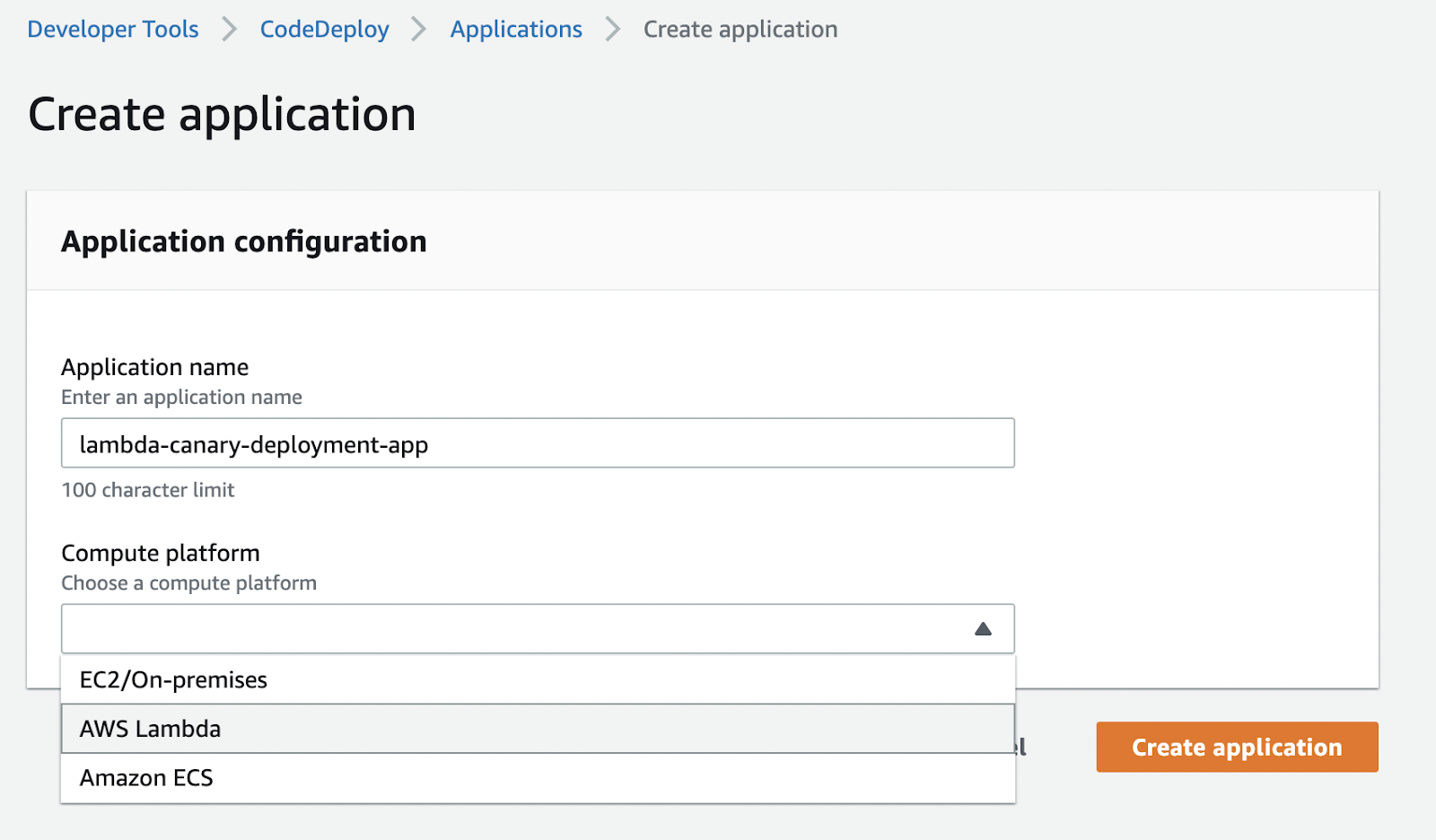
When creating a deployment group, we can choose from predefined deployment configurations or define our own.
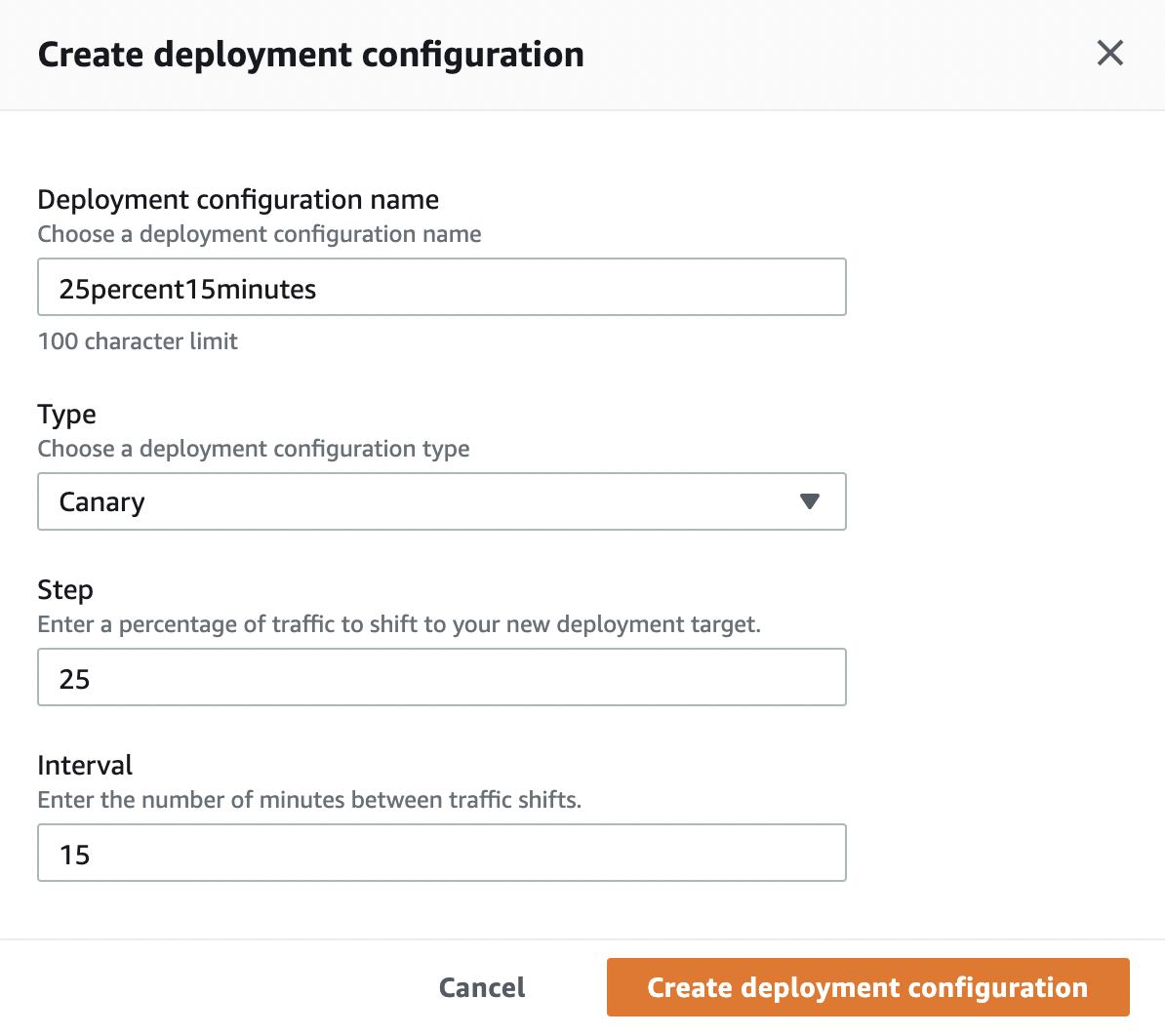
The last step is to do the actual deployment. We will use the following App Spec configuration to define our parameters. In the specification, we are telling CodeBuild to start weighted traffic from version 1 to version 2 on "canary-alias."
{
"version": "0.0",
"Resources": [
{
"lambda-canary-deployment-app": {
"Type": "AWS::Lambda::Function",
"Properties": {
"Name": "alias-dev-hello",
"Alias": "canary-alias",
"CurrentVersion": "1",
"TargetVersion": "2"
}
}
}
]
}
Once we save the changes, deployment will start.
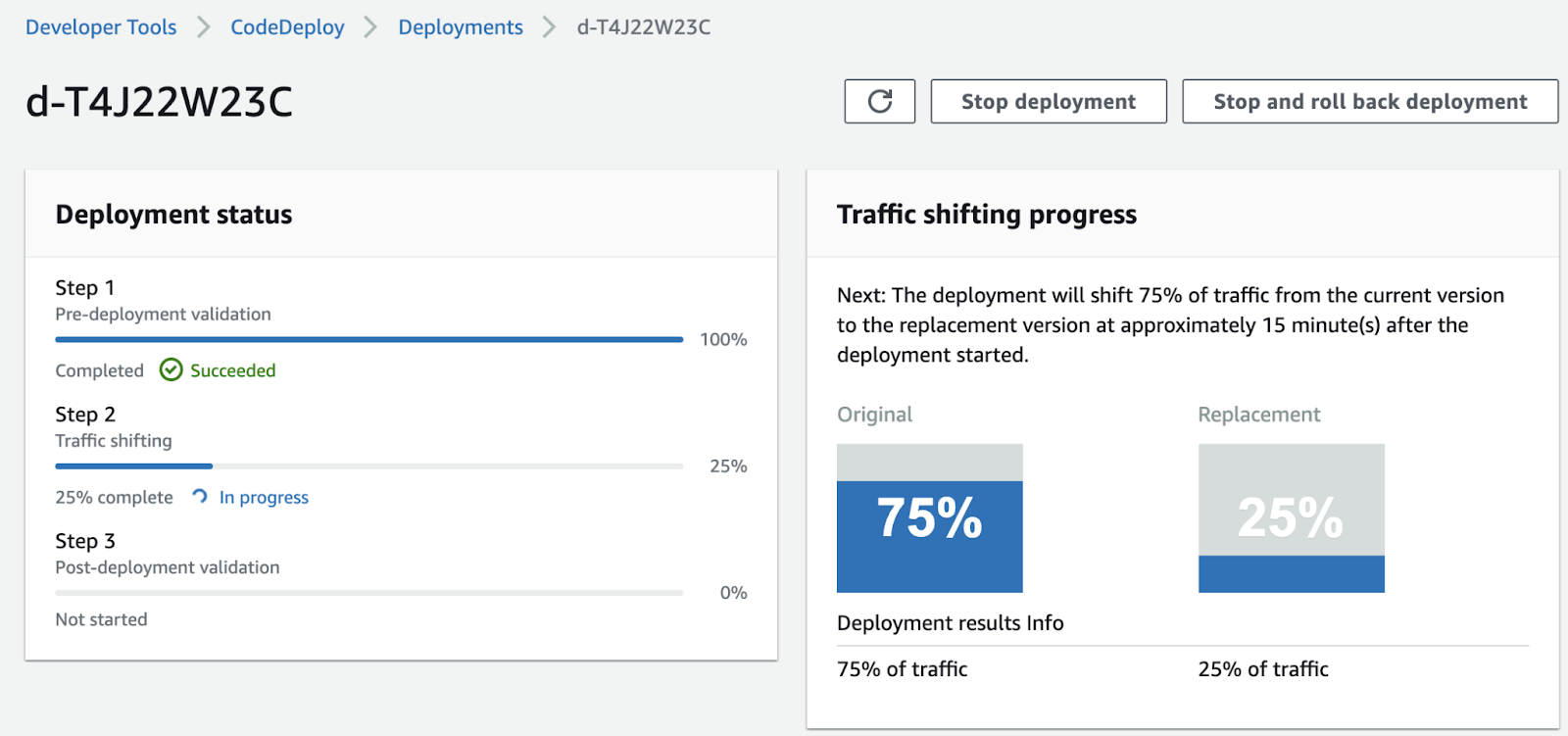
Rollback
Now that we know how to shift traffic, the last question remains. How to do rollback if the latest version does not work as expected? For this purpose, we will utilize Alarms and PreTraffic and PostTraffic hooks.
As the name suggests, the PreTraffic hook is a Lambda function executed just before traffic is shifted. If the Lambda doesn't return a successful response, traffic shifting is aborted.
The PostTraffic hook executes once traffic is shifted. If the Lambda doesn't return a successful response, rollback is initiated.
We can use these two Lambdas to run checks, tests, and validations against our deployed functions.
If we want to attach hooks to our deployment, our App Spec will now look as follows:
{
"version": "0.0",
"Resources": [
{
"lambda-canary-deployment-app": {
"Type": "AWS::Lambda::Function",
"Properties": {
"Name": "alias-dev-hello",
"Alias": "canary-alias",
"CurrentVersion": "1",
"TargetVersion": "2"
}
}
}
],
"Hooks": [
{
"BeforeAllowTraffic": "canary-production-preHook"
},
{
"AfterAllowTraffic": "canary-production-postHook"
}
]
}
Where "canary-production-preHook" and "canary-production-postHook" are the names of our validation Lambda functions.
Another valuable option to mention is Notification rules. CodeDeploy can send notifications to SNS or AWS Chatbot when the "Started", "Failed", or "Succeed" event occurs.
SAM Template
SAM templates comes with built-in support for CodeDeploy. We are showing relevant parts of the template in this article, while the full source code is available here
Resources:
Canary30Percent2Minutes:
Type: AWS::CodeDeploy::DeploymentConfig
Properties:
ComputePlatform: Lambda
DeploymentConfigName: Canary30Percent2Minutes
TrafficRoutingConfig:
Type: TimeBasedCanary
TimeBasedCanary:
CanaryInterval: 2
CanaryPercentage: 30
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: hello-world/
Handler: app.lambdaHandler
Runtime: nodejs14.x
AutoPublishAlias: live
DeploymentPreference:
Type: !Ref Canary30Percent2Minutes
As the name suggests "Canary30Percent2Minutes" is a custom deployment configuration for canary deployment with 30% initial traffic. After two minutes the rest of 70% of traffic will be shifted to the new version.
Serverless Canary Deployments Plugin
The nice thing about AWS is that there are so many options for deployments. In the previous section, we described how to set up gradual deployments using CodeDeploy and the AWS console.
In this example, we are going to use the Serverless framework and the "serverless-canary-deployments" plugin.
All we have to do is to add plugin and deployment settings to our serverless.yml file. This is the CSharp example, but it is based on the NodeJS example from the official plugin page.
Hello:
handler: CsharpHandlers::AwsDotnetCsharp.Hello::Handler
events:
- http:
method: get
path: hello
cors: true
deploymentSettings:
type: Linear10PercentEvery1Minute
alias: LATEST
preTrafficHook: before-allow-traffic-hook
postTrafficHook: after-allow-traffic-hook
before-allow-traffic-hook:
handler: CsharpHandlers::AwsDotnetCsharp.Before::Handler
after-allow-traffic-hook:
handler: CsharpHandlers::AwsDotnetCsharp.After::Handler
Full source code is available here.
To see the deployment in action, we need to change the "hello" function then deploy it to have another version to which CodeDeploy can switch traffic.
Conclusion
I hope that you enjoyed the content and found it helpful. Even though this is much longer than the usual "how-to" or "do it in 10 minutes" article, I firmly believe that it is crucial to talk about all related concepts. This can help promote better understanding and problem solving, which will inevitably happen at some point. And one final piece of advice that I always give: Don't just read the article and take it for granted. Go ahead, use the tools or console, make an application, explore options. The only way to learn it is to build it.



%20(1).svg)

.svg)









