

Introduction
The ability of AWS Lambda to integrate seamlessly with your favorite operational tools and services is one of its most appealing features. As a result, developers can construct spectacular cloud infrastructures, but they sometimes have trouble managing lambda function errors. As a result, this can lead to application downtime. Thankfully in this blog, we will go through how to properly handle function errors as we cover the following items:
- What is a lambda function error?
- How to gracefully handle a lambda function error
- Building a solution
What is a Lambda function error?
A lambda function error is when your function’s code throws an exception or returns an error object [1]. What are some possible causes for a function error? Imagine this scenario: you have a Lambda integration with Stripe to process payments. Your lambda function got invoked and sent a payment request to Stripe, but the request failed because Stripe’s service is down. While Stripe is quite reliable, this is just an example.
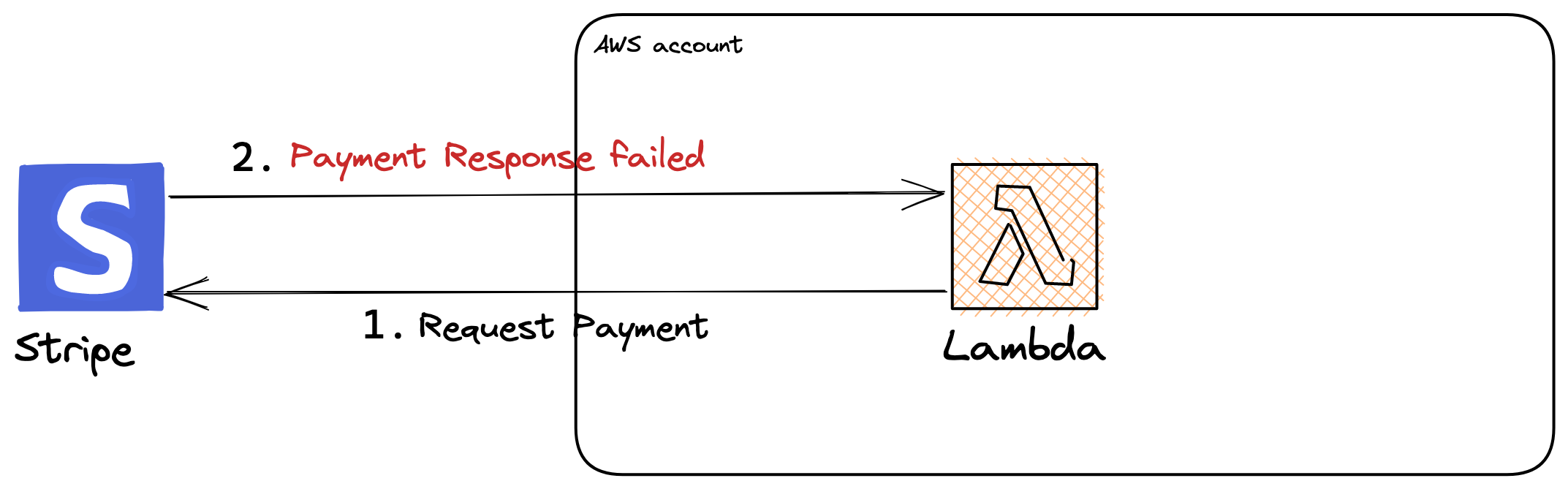
How to gracefully handle a Lambda function error?
One approach to handling a lambda function error is using Amazon Simple Queue Service (SQS). In the scenario described earlier, a queue would sit in-between Stripe and the Lambda function. If the Stripe service fails, SQS will store the failed messages in a dead-letter queue using a re-drive policy. This mechanism allows Lambda to re-process failed jobs. Isn’t that cool?
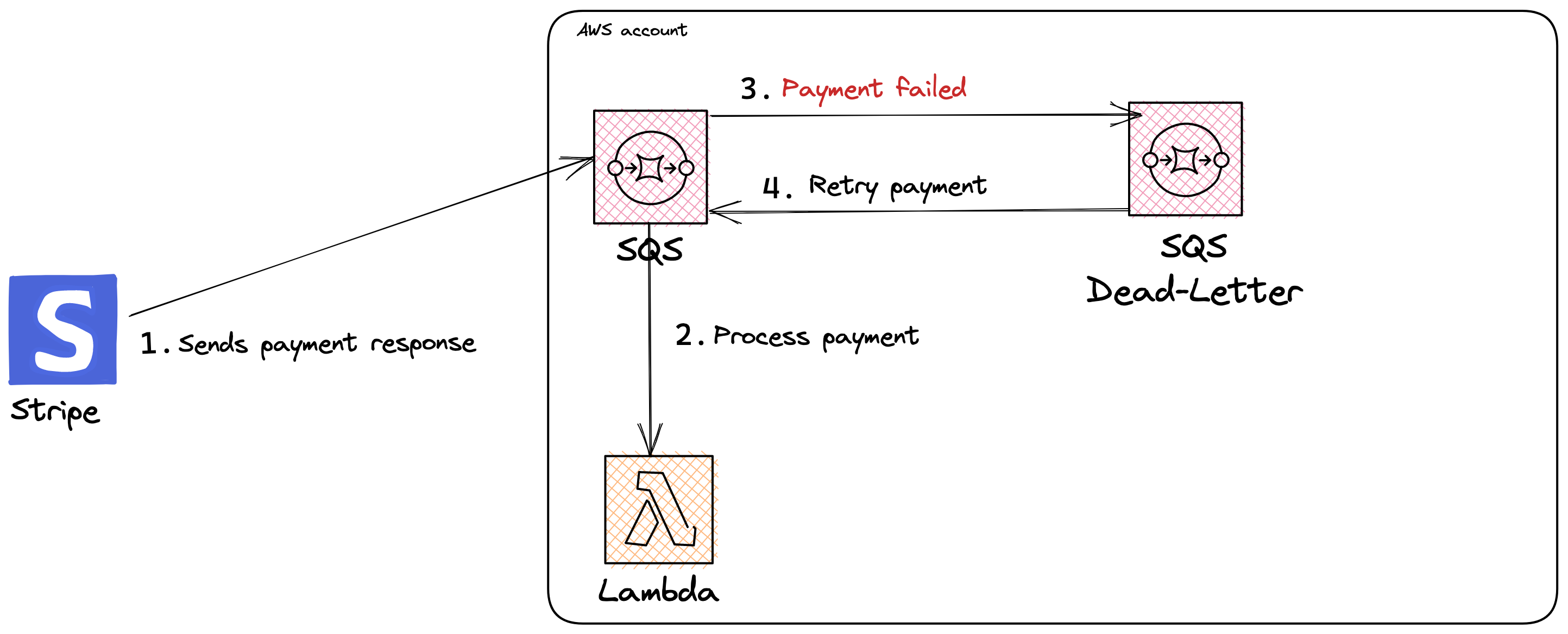
Building the solution
Init Serverless Framework
We will use the Serverless Framework tool to build our infrastructure. The below commands create a Serverless AWS NodeJs template app.
mkdir lambda-error-handling
cd lambda-error-handling
touch .env
sls create --template aws-nodejsConfigure AWS Credentials
Paste the following code into the '.env' file. Enter your personal AWS Access Key ID & Secret Access Key.
AWS_ACCESS_KEY_ID=<INSERT_ACCESS_KEY_ID>
AWS_SECRET_ACCESS_KEY=<INSERT_SECRET_ACCESS_KEY>Define Resources
- Standard Queue
- Dead-Letter Queue
- Lambda Function
Paste the following code into the 'serverless.yml' file. The 'deadLetterTargetArn' is a reference to a dead letter queue where failed jobs will be stored. If a job failed and the receive count for a message exceeds the 'maxReceiveCount', Amazon SQS moves the message to the dead-letter-queue.
#######################################################
# LAMBDA ERROR HANDLING #
# Happy Coding!! ;)) #
#######################################################
service: lambda-error-handling
frameworkVersion: "3"
provider:
name: aws
runtime: nodejs18.x
stage: dev
region: us-east-1
stackName: lambda-error-handling-${sls:stage}
# Allow usage of environment variables
useDotenv: true
## Lambda Function
functions:
Consumer:
handler: handler.consumer
name: ${self:provider.stackName}-Consumer
events:
- sqs:
arn: !GetAtt SourceQueue.Arn
# CloudFormation resource templates here
resources:
Description: >
This stack creates a solution for how to handle Lambda Function errors using Amazon Simple Queue Service (SQS).
Resources:
# Standard Queue
SourceQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: ${self:provider.stackName}-SourceQueue
RedrivePolicy:
deadLetterTargetArn: !GetAtt DLQueue.Arn # Defines where to store failed jobs
maxReceiveCount: 1
# Dead-Letter Queue
DLQueue:
Type: AWS::SQS::Queue
Properties:
QueueName: ${self:provider.stackName}-DLQueue
Outputs:
SourceQueueURL:
Description: "Source Queue URL"
Value: !Ref SourceQueue
Export:
Name: ${self:provider.stackName}-SourceQueue
DeadLetterQueueURL:
Description: "Dead-Letter Queue URL"
Value: !Ref DLQueue
Export:
Name: ${self:provider.stackName}-DLQueueCreate code for Lambda
The function code is pretty basic. We are simulating a Stripe payment request/response. It simply reads a message from the queue and runs a conditional check. The function will throw an error if the message content is 'PYMT_FAILED'. Otherwise, if the message content is 'PYMT_SUCCEED' the function will run as normal and return a successful response.
Paste the following code into the 'handler.js' file.
module.exports.consumer = async (event) => {
const { Records } = event; // gets Record payload from Queue
let body = Records[0]?.body; // get msg from body
if (body === "PYMT_FAILED") {
throw new Error("Payment request failed");
} else if (body === "PYMT_SUCCEED") {
return {
statusCode: 200,
body: JSON.stringify("Payment request succeeded!"),
};
}
};Deploy Infrastructure
sls deploy --verbose
Once the stack is successfully deployed, you can go to CloudFormation in the AWS console and retrieve the URL for the Source Queue and the Dead Letter Queue.
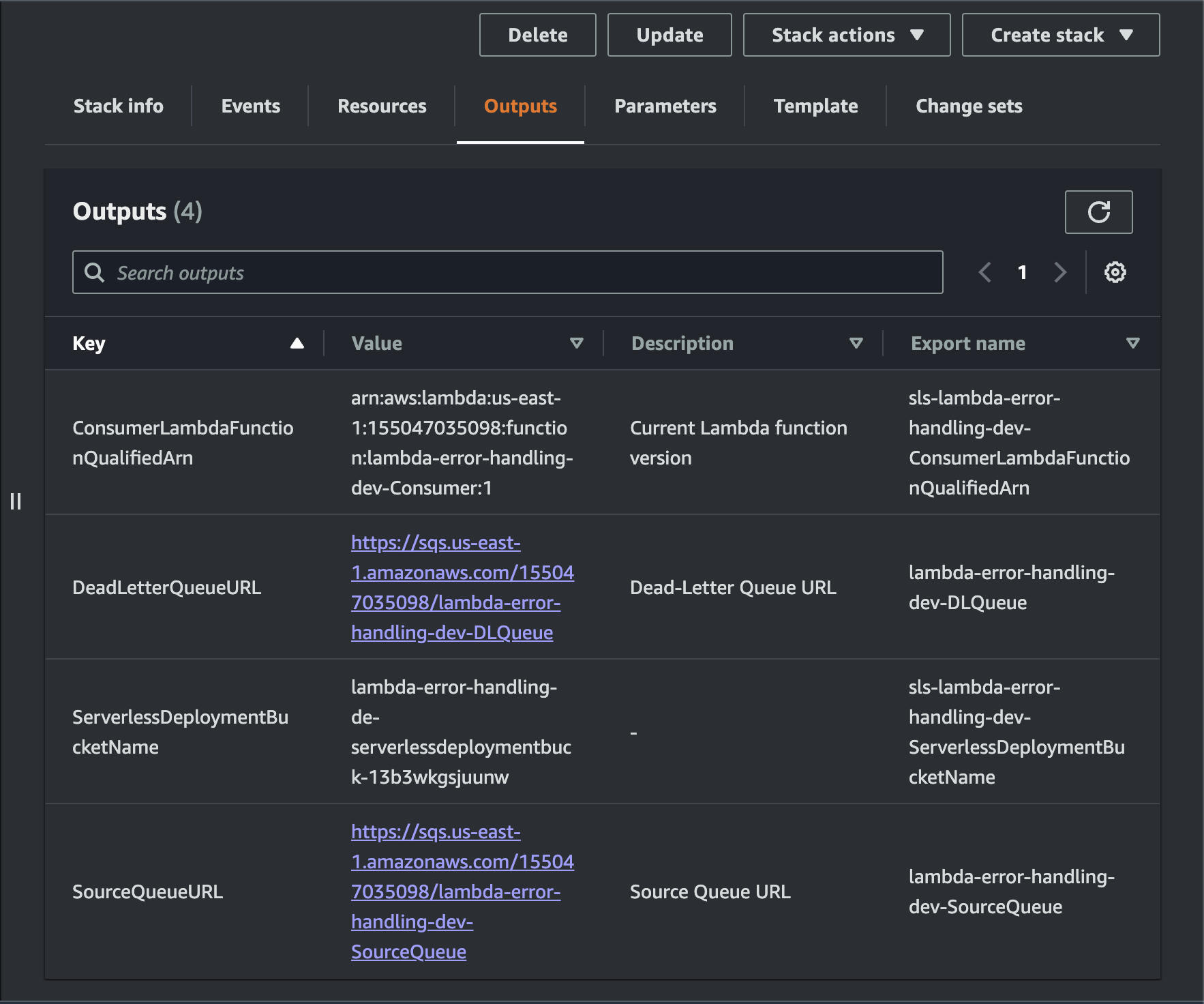
Sending Messages to the Queue
We are simulating the process of sending a Stripe failed payment response. For the queue URL, enter the Source Queue URL:
aws sqs send-message
--queue-url <INSERT_SOURCE_QUEUE_URL>
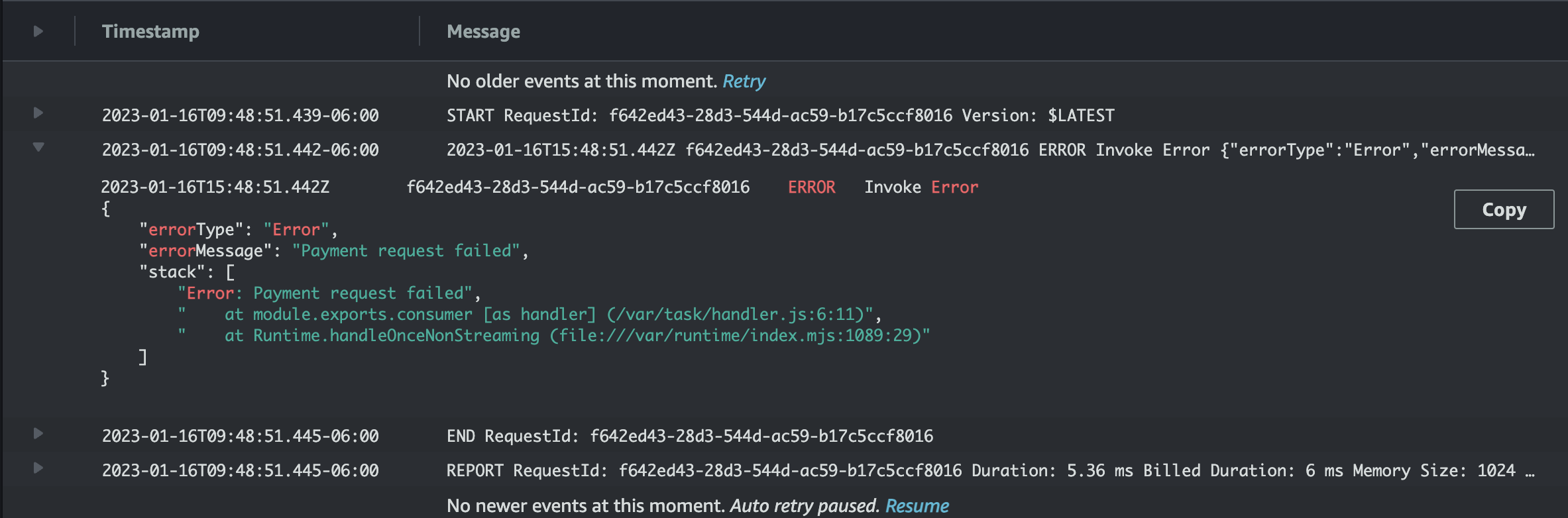
--message-body "PYMT_FAILED"Inspect Lambda Function Logs
Now, if we inspect the logs for the lambda function, we can see the function threw an error.
Inspect Dead-Letter Queue
Paste the following command in your terminal:
aws sqs receive-message
--queue-url <DEADE_LETTER_QUEUE_URL> The command displays the failed message that is stored in the dead-letter queue.
{
"Messages": [
{
"MessageId": "69ecc6ce-ce88-4b10-a451-4486551054f7",
"ReceiptHandle": "AQEBnMZlNKkSvuum76Zfbo6GUE62J5RAayDcERnngeecDw/yVIJCS7an3B7XplzlTBwbsDEthtZuy7AMbZuyhCl+elfWwCMIryeRkZ4NUWmfOPgJp7lW86IMU4tW+H3eSsR6KvvniX9LR0o1T5TqUJVomO1IJQtmng39u9ZS8/8ualkmtm7GtgyVVGZTUoIW1yluUc5YPpWPQhBxFgFNu7qoQ8387IbcpSxMh9N8fiOOsKCn+tcKv4vuIB16T7e5czQAjwfK2rHoDWTbhDlhA3ysvH+CL8zVkig2PHyKdJ3oTq1r50dGKW57TO/ZpybNAFYUTv/9/xbqApvoLgzK7EMRWXbT5EXTfYJuogb2bz3toESolwNNTnEkXwz0Jxo/Ktuygenf4v2GqourRzMHXMg0cBTctDAKP35mPplSoNkAbTM=",
"MD5OfBody": "c3a9a8906969626705d98898392ddc75",
"Body": "PYMT_FAILED"
}
]
}Start a Re-drive
Currently, I am not aware if there is a process to trigger a queue re-drive programmatically. Great opportunity to let AWS know this feature is highly needed. We can start the re-drive using the AWS Console. Head over to the AWS Console and search for SQS and select the Dead-Letter Queue we created earlier. Starting a re-drive will submit the message to the original source queue and trigger the lambda function to re-process the message.
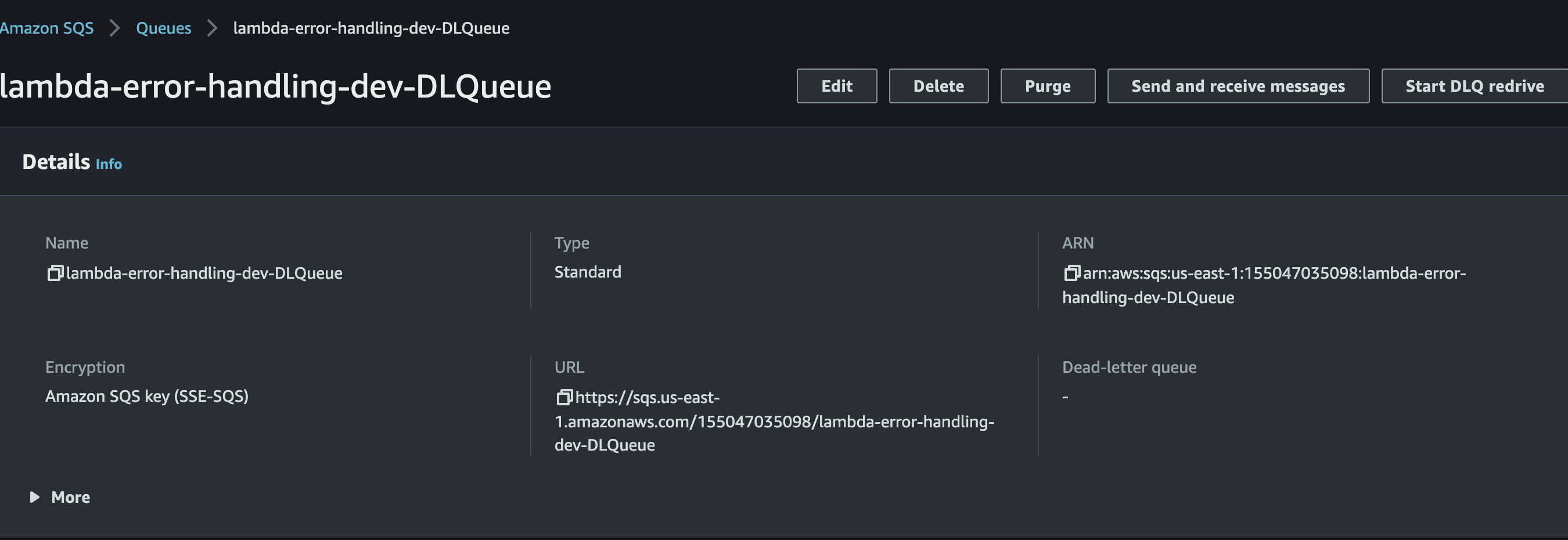
Conclusion
In this article, you have seen what a Lambda Function error is and one approach to properly handling the error using a dead-letter queue. As a next step, you can extend the architecture further by adding alarms for when the queue has reached its maximum re-drive policy.
You can find the complete source code on my GitHub.
For any questions, comments, or concerns, please feel free to message me on LinkedIn or Twitter.
Happy building & have a great day!
References
[1] : https://docs.aws.amazon.com/lambda/latest/dg/invocation-retries.html



%20(1).svg)

.svg)









