This is continuing from Part One of getting set up using Pulumi.
Software testing is generally meant to verify if one’s system is working as intended without any gaps or errors.
When it comes to the deployment of cloud infrastructure, there are quite a number of things that can go wrong. For instance, provisioning resources that handle sensitive data without specific access restrictions, or creating a resource with the intention of performing one task but not having it quite work as intended.
Thankfully, it is possible to perform tests in such situations with Pulumi.
Pulumi is an Infrastructure as Code (IaC) tool that leverages general-purpose programming languages for provisioning cloud resources with multi-cloud support. Owing to its conducive implementation, integrating with other infrastructure or configuration management tools is a simple task.
In this article, we’ll look into creating a serverless function with Pulumi’s SDK and then explore how to perform tests on the program.
Pulumi program setup and deployment.
The function we’ll create will get invoked when new entries are added to a DynamoDB table. On invocation, the function will get the text content and call the AWS Polly service for converting the text-to-speech, and then store the audio file in an S3 bucket.
Before we can write the program, the SDK needs to be installed. Follow their quick start guide here.
Python is the language we will use to write the program and perform tests. To install python if you don’t have it already, the instructions can be followed from this link.
Once the SDK and the language runtime is installed, inside an empty directory execute this command
pulumi new aws-python
If there are multiple AWS profiles configured with your AWS CLI, can specify the profile that should be used by Pulumi for deployments by running,
pulumi config set aws:profile <profilename>
The Pulumi program goes inside the ‘__main__.py’ file. Replace the contents of that file with this code.
"""An AWS Python Pulumi program"""
import pulumi
from pulumi_aws import s3,lambda_,iam,dynamodb
# Create bucket to store transcribed audio file
bucket_tts = s3.Bucket(
resource_name='slsguru-tts-bucket',
bucket="<YOUR_BUCKET_NAME>",
)
# Create dynamoDB table containing text entries
ddb = dynamodb.Table(
resource_name="ttsslsguru",
name="ttsslsguru", # this disables auto-naming
billing_mode="PAY_PER_REQUEST",
attributes=[
{
"name": "Id",
"type": "N",
},
],
hash_key="Id",
stream_enabled=True,
stream_view_type='NEW_IMAGE',
)
# Create Lambda IAM lambda_role
lambda_role = iam.Role(
resource_name='lambda-tts-iam-role',
assume_role_policy="""{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow",
"Sid": ""
}
]
}"""
)
# Attach policy to the role
lambda_role_policy = iam.RolePolicy(
resource_name='lambda-tts-iam-policy',
role=lambda_role.id,
policy="""{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"s3:PutObject",
"polly:SynthesizeSpeech",
"dynamodb:*"
],
"Resource": "*"
}
]
}"""
)
# Create Lambda function and attach the created role
lambda_fn = lambda_.Function(
resource_name='slsguru-tts',
role=lambda_role.arn,
runtime="python3.6",
handler="lambdatts.lambda_handler",
code=pulumi.AssetArchive({
'.': pulumi.FileArchive('.')
}),
timeout=30,
memory_size=128,
)
# Allow lambda to get events
lambda_event = lambda_.EventSourceMapping(
resource_name="ddb_stream_event",
event_source_arn=ddb.stream_arn,
function_name=lambda_fn.arn,
starting_position="LATEST",
maximum_batching_window_in_seconds=2
)
# Export created assets (buckets, lambda function)
pulumi.export('Text_bucket', bucket_tts.id)
pulumi.export('table', ddb.arn)
pulumi.export('lambda function', lambda_fn.arn)In the root of your directory, create a python file that will contain the code for the function’s handler. (Be sure to match the handler value for the lambda object in the above program to the file name you create).
import boto3
import os
from contextlib import closing
def lambda_handler(event, context):
for record in event['Records']:
dynamodb_record = record["dynamodb"]
textID = dynamodb_record["Keys"]["Id"]["N"]
text_content = dynamodb_record["NewImage"]["text"]
print("Text to Speech function. Text ID in DynamoDB: {}".format(textID))
#For each block, invoke Polly API, which will transform text into audio
polly = boto3.client('polly')
response = polly.synthesize_speech(
OutputFormat='mp3',
Text = text_content["S"],
VoiceId = "Joey")
#Save the audio stream returned by Amazon Polly on Lambda's temp directory.
if "AudioStream" in response:
with closing(response["AudioStream"]) as stream:
output = os.path.join("/tmp/", textID)
with open(output, "wb") as file:
file.write(stream.read())
s3 = boto3.client('s3')
s3.upload_file('/tmp/' + textID,
'<YOUR_BUCKET_NAME>',
textID + ".mp3")
returnYou can deploy the program to AWS by just executing
pulumi up
Based on how the program is written, Pulumi will automatically provision to reach the resource’s desired state.
Once the deployment is successful, insert any random text data into the dynamoDB table, ensuring that the content is entered against a ‘text’ attribute because the handler function is programmed to look for one. The converted text-to-speech mp3 file will be present in the bucket specified when the function finishes executing.
Testing with Pulumi:
Since these programs can be written in general-purpose programming languages, Pulumi makes it possible to take advantage of native testing frameworks for running automated tests. Pulumi supports three styles of performing automated tests for cloud programs.
Unit testing:
The nature of these tests is to evaluate the behavior of your code in isolation. Running in-memory, the external dependencies for these tests are replaced by mocks. They are authored in the same language as the Pulumi program. The focus of these tests is not on the behavior of the cloud resources but rather on their inputs.
For instance, we can create unit tests for the above program that verify three things.
- Lambdas should have a minimum timeout of 30 sec.
- Buckets to have ‘bucket’ parameter. Meaning that bucket’s auto-naming by Pulumi should be disabled.
- DynamoDB table should have ‘stream_view_type’ attribute value as ‘NEW_IMAGE’
At the project root, make a copy of the above Pulumi program into another file. Inside a new python file place the following unit tests code.
import unittest
import pulumi
class MyMocks(pulumi.runtime.Mocks):
def new_resource(self, type_, name, inputs, provider, id_):
return [name + '_id', inputs]
def call(self, token, args, provider):
return {}
pulumi.runtime.set_mocks(MyMocks())
# It's important to import the program after the mocks are defined.
import <your_pulumi_program_copy_filename> as infra
class TestingWithMocks(unittest.TestCase):
# check 1: Lambdas should have a minimum timeout of 30sec.
@pulumi.runtime.test
def test_lambda_timeout(self):
def check_timeout(args):
urn, timeout = args
self.assertIsNotNone(timeout, f'lambda {urn} must have timeout')
self.assertGreaterEqual(timeout,30,f'lambda {urn} must have a timeout greater or equal to 30')
return pulumi.Output.all(infra.lambda_fn.urn, infra.lambda_fn.timeout).apply(check_timeout)
# check 2: Bucket to have 'bucket' parameter.
@pulumi.runtime.test
def test_bucket_name(self):
def check_name(args):
urn, bucket = args
self.assertIsNotNone(bucket, f'Bucket {urn} must have a bucket parameter with a name')
return pulumi.Output.all(infra.bucket_tts.urn, infra.bucket_tts.bucket).apply(check_name)
# check 3: DynamoDB table should have stream_view_type as NEW_IMAGE
@pulumi.runtime.test
def test_dynamodb_stream_type(self):
def check_stream_view(args):
urn, stream_view_type = args
self.assertIsNotNone(stream_view_type, f'Table {urn} should have stream_view_type parameter')
self.assertEqual('NEW_IMAGE',stream_view_type,f'Table should have NEW_IMAGE as stream view type value')
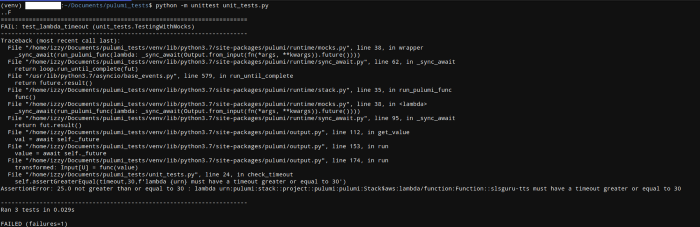
return pulumi.Output.all(infra.ddb.urn, infra.ddb.stream_view_type).apply(check_stream_view)Alter the program’s values such that tests fail. Utilizing the python’s built-in test framework, unit test, we’ll execute these tests by running the command
python -m unittest <unit_test_filename>
Property testing:
These tests are executed while the resources are being deployed. They are based on Pulumi’s offering called CrossGuard (Policy as code). While Policy as Code and Property Testing both use the same technology, the goals and workflows are different. As opposed to unit testing, property tests can evaluate real values returned from the cloud provider instead of the mocked ones. Property tests are limited to Node.js and Python only.
To implement property testing, create a folder ‘tests’ at project root. Create ‘__main__.py’ and ‘PulumiPolicy.yaml’ inside that folder. Install pulumi’s policy pack library by running
pip install pulumi-policy
Add this to PulumiPolicy.yaml.
description: A minimal Policy Pack for AWS using Python.
runtime: python
version: 0.0.1Place this inside the __main__.py of the ‘tests’ folder.
from pulumi_policy import (
EnforcementLevel,
PolicyPack,
ReportViolation,
ResourceValidationArgs,
ResourceValidationPolicy,
)
import json
# Check for DynamoDB stream enabled value
def dynamodb_stream_validation(args: ResourceValidationArgs, report_violation: ReportViolation):
if args.resource_type == "aws:dynamodb/table:Table" and "streamEnabled" in args.props:
stream_value = args.props["streamEnabled"]
if stream_value != True:
report_violation("For this program to work DynamoDB streams need to be enabled")
stream_check = ResourceValidationPolicy(
name="dynamodb_stream_check",
description="Check if streams are enabled.",
validate=dynamodb_stream_validation,
)
# Check if policies are included
def iam_policy_validation(args: ResourceValidationArgs, report_violation: ReportViolation):
if args.resource_type == "aws:iam/rolePolicy:RolePolicy" and "policy" in args.props:
policy = json.loads(args.props["policy"])
policies = policy["Statement"][0]["Action"]
if "s3:PutObject" not in policies or "polly:SynthesizeSpeech" not in policies:
report_violation("For this program to work S3 and Polly policies needed")
policy_check = ResourceValidationPolicy(
name="s3-polly-policy",
description="Check if permissions are present.",
validate=iam_policy_validation,
)
PolicyPack(
name="aws-python",
enforcement_level=EnforcementLevel.MANDATORY,
policies=[
stream_check,
policy_check
],
)These tests verify two items: the dynamoDB table must have streams enabled for the lambda function to get invoked, and the policy attached to the lambda role must have permissions for S3 and Polly services.
To run these tests, execute
pulumi up --policy-pack tests
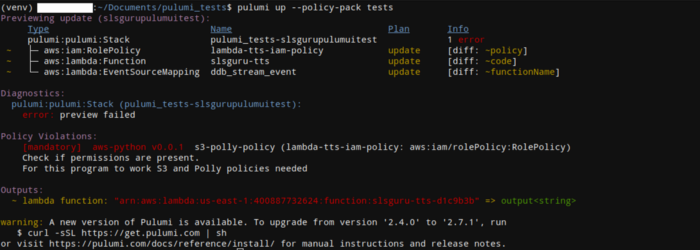
It’s only when the tests pass that deployment will proceed. This way you can ensure the created resources on the cloud are compliant with your project’s requirements.
Integration testing:
This form of testing runs the program in combination with Pulumi CLI to deploy the resources to an ephemeral environment. After running tests on the created infrastructure, the resources are destroyed. The prime responsibility of these tests is to ensure that the project is deployed to the expected state, and the programmed logic works as intended. The duration for these tests is considerably longer (in minutes) in comparison to the above variations.
Pulumi has an extensive set of integration tests written in Go. You can utilize their Go test framework irrespective of the language your Pulumi program is written in. Although, presently, support for integration tests for other languages from Pulumi aren’t available. If you would like to explore, there is a community developed framework for python called Pitfall.
Conclusion:
By utilizing Pulumi’s testing concepts, you can ensure that the provisioning of resources is in line with your project’s requirements and the system works as intended. Migration to Pulumi for programs created with other tools is certainly possible by following their strategy from this doc. Not only that, but Pulumi also has a tool, tf2pulumi, that converts the IaC code written for Terraform in HCL (HashiCorp Configuration Language) to a Pulumi program. They also have integrations for any continuous integration/continuous delivery (CI/CD) system. Writing infrastructure deployment programs with Pulumi is simplified because you have the option to choose the language for creating the program.



%20(1).svg)

.svg)