When tackling data processing tasks, teams often face a choice between using specialized data engineering tools or adopting solutions that align more closely with their existing expertise. Specialized tools can be incredibly powerful, offering advanced capabilities for distributed processing and complex workflows. However, they often require a deep understanding of specific frameworks or paradigms, which may introduce a learning curve or demand a shift in problem-solving approaches.
For our use case—processing CSV data and storing it in DynamoDB—we sought a solution that would balance scalability, flexibility, and ease of use. AWS Step Functions' distributed map state stood out as an ideal choice. It provides a serverless, low-code approach to orchestrating parallel tasks, making it accessible to developers and engineers without requiring extensive knowledge of distributed data processing frameworks.
By leveraging Step Functions, we can focus on solving the problem at hand while benefiting from its ability to scale efficiently and handle batch processing with minimal overhead. This approach allows us to streamline our workflow and optimize performance without introducing unnecessary complexity.
What to Expect
In this article, I’ll share practical insights and experiences from using the Step Functions Distributed Map State to efficiently process large datasets stored in Amazon S3. Step Functions offers a serverless, low-code solution for orchestrating workflows through state machines, enabling scalable application development, process automation, and streamlined data pipeline orchestration.
We will explore how Step Functions integrates seamlessly with the AWS SDK, allowing workflows to invoke nearly any AWS service API directly. You’ll also learn about defining workflows using Amazon States Language (ASL), designing them visually in Workflow Studio within the AWS Management Console, or building them locally with the AWS Toolkit for Visual Studio Code.
This article will demonstrate how to set up and use a Distributed Map State to process a CSV file containing order records stored in Amazon S3 and load this data into a DynamoDB table efficiently. By walking through this approach, we aim to provide actionable insights into leveraging Step Functions for batch processing while helping you make informed decisions about selecting tools that align with your team’s expertise and project requirements.
Solution Architecture Overview
This diagram illustrates the architecture for processing large datasets using AWS Step Functions' Distributed Map State. The workflow is designed to handle CSV files stored in Amazon S3 and load the processed data into DynamoDB efficiently.
.webp)
Let’s break down the key components:
- Source CSV in Amazon S3: The process begins with a CSV file stored in an Amazon S3 bucket. This file serves as the input dataset for the workflow.
- Orchestrator Workflow: The orchestrator, implemented as a Step Functions state machine, initiates and manages the entire process. It splits the input dataset into smaller batches for parallel processing, enabling scalability.
- Distributed Map Runs: The Distributed Map State is at the core of this architecture. It divides the workload into multiple child workflows, each responsible for processing a batch of data. These child workflows run concurrently, leveraging Step Functions' ability to execute up to 10,000 parallel workflows.
- Child Workflows: Each child workflow processes its assigned batch of data. This typically involves invoking Lambda functions or other AWS services to transform and prepare data for storage.
- Amazon DynamoDB: Once processed, the data from each batch is loaded into an Amazon DynamoDB table. DynamoDB serves as the final destination for storing structured and queryable data.
- Distributed Map Output: The results of all child workflows are aggregated and written back to Amazon S3 or another specified location for further analysis or auditing.
This design leverages Step Functions' Distributed Map State to achieve high concurrency and scalability while maintaining simplicity and flexibility in orchestrating complex workflows. By breaking down large datasets into manageable batches and processing them in parallel, this solution ensures efficient handling of big data workloads without overwhelming downstream services like DynamoDB.
Solution Architecture and Workflow Design
The diagram above illustrates the architecture for processing large datasets using AWS Step Functions' Distributed Map State. At its core, this design leverages two workflows—the Parent Workflow and the Child Workflow—to efficiently orchestrate and execute batch processing tasks.
Parent Workflow
The Parent Workflow acts as the orchestrator of the entire process. It is implemented as a Standard Workflow and includes a Distributed Map State. This state is responsible for splitting the input CSV file stored in Amazon S3 into smaller batches. Each batch is then sent to the Child Workflow for independent processing. The Parent Workflow ensures scalability by enabling parallel execution of multiple child workflows, making it ideal for handling large datasets.
Child Workflow
The Child Workflow, also known as the Batch Processor, processes each batch independently. It performs transformations, validations, and writes the processed data into DynamoDB. By isolating batch processing within individual workflows, this design achieves modularity and ensures that failures or delays in one batch do not impact others.
This architecture enables efficient data pipeline orchestration by leveraging Step Functions' ability to execute nested workflows. The modular separation between Parent and Child Workflows simplifies error handling, monitoring, and scaling.
Note on JSONata
This implementation leverages JSONata for transforming and querying data within the workflows. JSONata is integral to dynamically shaping input data for Child Workflows during execution, enabling flexibility in managing diverse datasets. While this section provides a brief overview of JSONata’s role, its detailed usage will be covered in the code walkthrough later in the article.
If you’re new to JSONata or wish to learn more about its capabilities, you can refer to its documentation.
As part of this implementation, we use JSONata for transforming and querying data within the workflows. JSONata plays a crucial role in dynamically shaping input data for child workflows during execution. While we won’t dive deeply into JSONata here, it will be covered in the code walkthrough section where its usage becomes more apparent. If you're unfamiliar with JSONata, you can explore its documentation to learn more.
AWS Step Functions Map State: Inline vs. Distributed Processing
AWS Step Functions provides two processing modes for the Map state: Inline and Distributed. Each mode is designed for specific use cases, offering distinct advantages depending on the scale and concurrency needs of your workflow.
Inline Map State
The Inline Map State enables you to repeat a series of steps for each item in a collection, such as a JSON array, within the execution context of the parent workflow. This means that all iterations share the same execution history and logs, which are recorded alongside the parent workflow's history.
Key Features
- Concurrency Control: Inline Map State supports up to 40 concurrent iterations, configurable using the
MaxConcurrencyfield. This allows you to balance parallel processing with resource constraints. - Unified Execution History: All iterations are logged within the parent workflow's execution history, making it easier to trace and debug workflows without switching contexts.
- Input Requirements: Inline mode accepts only a JSON array as input, making it ideal for workflows where data is structured as arrays.
Use Cases
Inline Map State is best suited for workflows that:
- Require limited concurrency (up to 40 parallel iterations).
- Need unified execution history for easier monitoring and debugging.
- Operate on smaller datasets or involve lightweight operations.
How It Works
The Inline Map State processes each item in the input array sequentially or in parallel (based on MaxConcurrency) within the parent workflow’s execution context. This design is particularly useful for workflows where maintaining a single execution trace is critical or where scalability requirements are modest.
The diagram below illustrates how Inline Map State processes items in a collection:
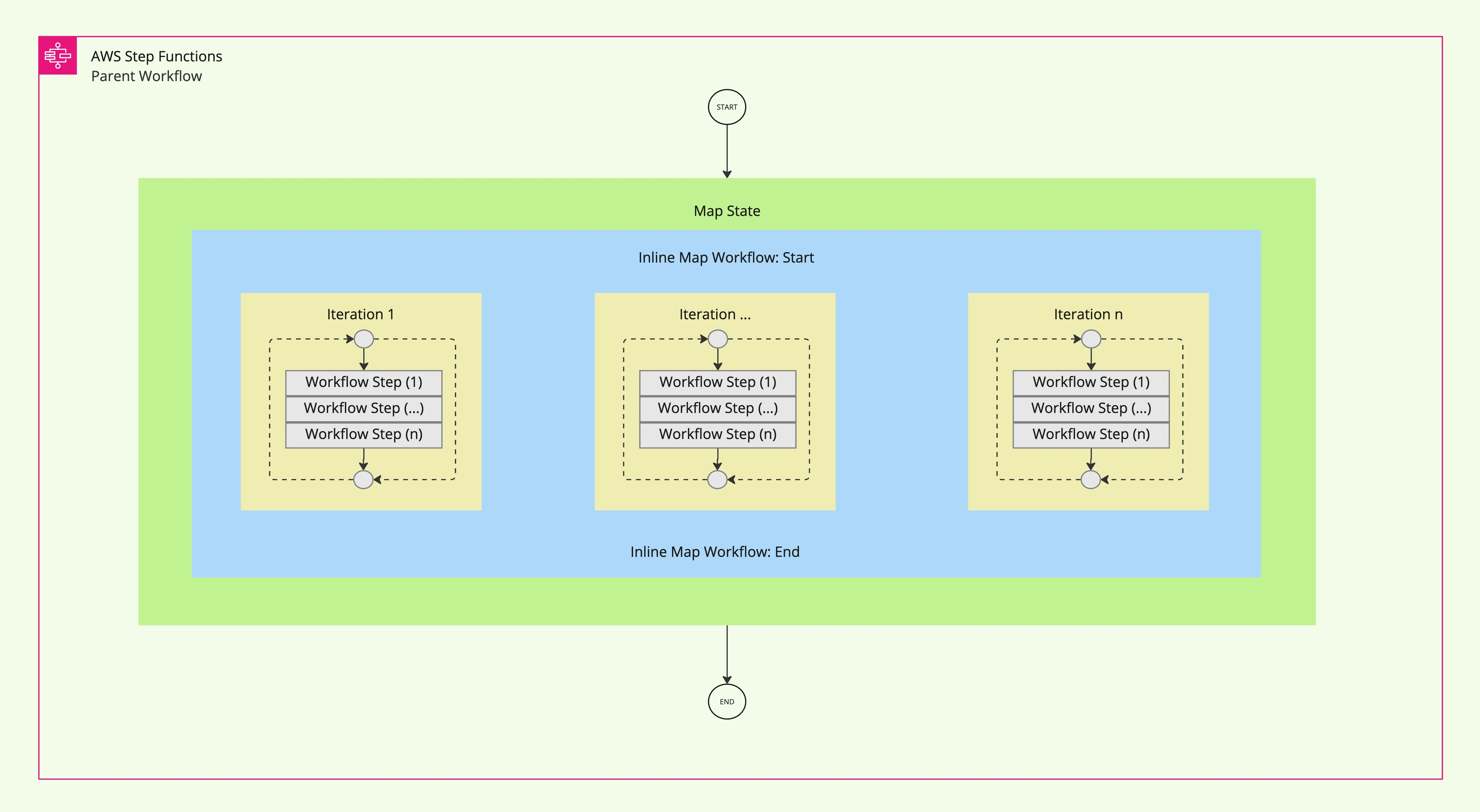
- The Map State iterates over a collection of items (e.g., JSON array).
- For each iteration, a series of workflow steps (Workflow Step 1, Workflow Step n) are executed sequentially or concurrently.
- The results of all iterations are aggregated into the parent workflow’s output.
Limitations
While Inline Map State is powerful for small-scale operations, it may not be suitable for workflows requiring:
- High concurrency (more than 40 parallel iterations).
- Large datasets exceeding 256 KiB.
- Separate execution histories for individual iterations.
For such scenarios, consider using the Distributed Map State, which offers higher scalability and flexibility.
Distributed Map State
The Distributed Map State is a processing mode in AWS Step Functions designed for large-scale parallel data processing. Unlike the Inline Map State, which operates within the execution context of the parent workflow, Distributed Map launches child workflows to process each item in a dataset independently. This makes it ideal for handling massive datasets that exceed the limitations of Inline mode, such as size constraints or concurrency requirements.
Key Features of Distributed Map State
- High Concurrency: Supports up to 10,000 parallel executions by default, configurable via the
MaxConcurrencysetting. - Independent Execution Histories: Each child workflow has its own execution history, separate from the parent workflow. This prevents exceeding the maximum output payload size for the parent workflow.
- Flexible Input Sources: Accepts input as a JSON array or references data stored in Amazon S3 (such as CSV files or lists of objects).
- Scalability: Ideal for workloads requiring high concurrency, modularity, and scalability, such as processing millions of S3 objects or transforming large CSV files.
How It Works
The diagram below illustrates how Distributed Map State orchestrates large-scale parallel processing:
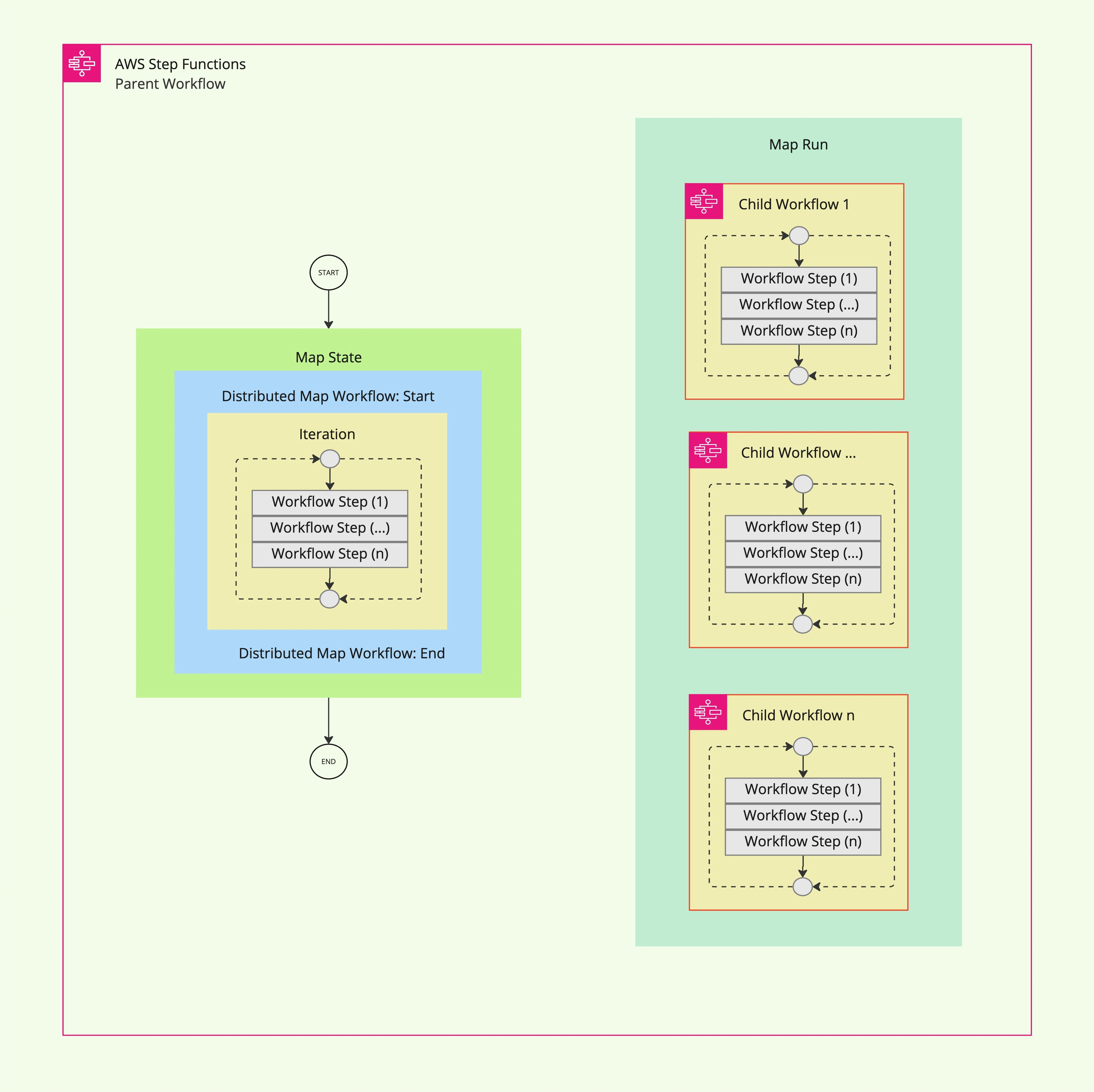
When the parent workflow invokes a Distributed Map State:
- The parent workflow passes either a JSON array or an Amazon S3 data source as input.
- Step Functions creates a Map Run resource to manage the execution of child workflows.
- Each child workflow processes individual items or batches from the dataset independently. These workflows perform specific tasks such as data transformation and validation (e.g., Workflow Step 1 to Workflow Step n).
- Results from all child workflows can be aggregated and exported to Amazon S3 or other destinations.
This architecture enables high concurrency while maintaining modularity and scalability. It is especially effective for workflows requiring distributed processing across large datasets stored in Amazon S3.
Use Cases
Distributed Map State is particularly useful for:
- Datasets exceeding 256 KB in size.
- Workflows requiring more than 40 concurrent iterations.
- Scenarios where execution histories would exceed 25,000 entries.
By leveraging Distributed Map State, teams can orchestrate serverless workflows that efficiently process large-scale data while overcoming limitations of Inline mode. This ensures faster processing times and greater flexibility for complex applications.
Parent Workflow Implementation: Detailed Walkthrough
The parent workflow serves as the orchestrator of the batch processing operation, leveraging the Distributed Map state to process large datasets efficiently. As shown in the diagram, the workflow begins by reading a CSV file from S3 and then uses a Distributed Map state to process and store the data in batches.
.webp)
Distributed Map State Configuration in Detail
The Distributed Map state is the core component that enables high-concurrency processing by creating separate child workflow executions for each batch of data. Here's a breakdown of its configuration:
{
"Comment": "Batch processing of Orders for storage in DynamoDB",
"StartAt": "Read CSV file from S3",
"States": {
"Read CSV file from S3": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "Write a batch of items to DynamoDB table",
"States": {
"Write a batch of items to DynamoDB table": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution",
"Arguments": {
"StateMachineArn": "arn:aws:states:{{{AWS::Region}}}:{{{AWS::AccountId}}}:stateMachine:write-to-ddb",
"Input": "{% $states.input %}"
},
"End": true,
"Output": {
"childWfOutput": "{% $states.result %}"
}
}
}
},
"End": true,
"Label": "ReadCSVfilefromS3",
"MaxConcurrency": 50,
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW",
"CSVDelimiter": "COMMA",
"MaxItems": 10000
},
"Arguments": {
"Bucket": "<s3Bucket>",
"Key": "<s3Prefix>/<csvFile>"
}
},
"ItemSelector": {
"pk": {
"S": "{% $states.context.Map.Item.Value.orderNumber & '-' & $states.context.Map.Item.Value.orderDate %}"
},
"sk": {
"S": "ORDER_HEADER"
},
"orderStatus": {
"S": "{% $states.context.Map.Item.Value.orderStatus %}"
},
"totalPrice": {
"S": "{% $states.context.Map.Item.Value.totalPrice %}"
}
},
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Arguments": {
"Bucket": "<s3Bucket>",
"Prefix": "<s3Prefix>"
},
"WriterConfig": {
"OutputType": "JSON",
"Transformation": "COMPACT"
}
},
"ItemBatcher": {
"MaxItemsPerBatch": 10,
"BatchInput": {
"ddbTable": "orders"
}
}
}
},
"QueryLanguage": "JSONata"
}
{
"orderNumber": "ON123456",
"orderDate": "2025-02-25",
"orderStatus": "OPEN",
"lineItems": 2,
"totalPrice": "106.3"
}
Essential Configuration Components
The Distributed Map state creates separate child workflow executions for each batch, enabling high-concurrency processing of large datasets.
1. ItemProcessor Configuration
- ProcessorConfig.Mode: Must be set to "DISTRIBUTED" to enable distributed processing
- ProcessorConfig.ExecutionType: Determines the type of child workflows
- "EXPRESS" for shorter-duration, higher-throughput workloads
- "STANDARD" for longer-running workloads with visible execution history
The parent workflow must always be a Standard workflow, regardless of child workflow type2. ItemReader Configuration (for S3 Data Sources)
- Specifies the dataset and its location
- Note: This field is omitted when the input is a JSON array from a previous state
- Supports multiple formats including CSV and JSON
- MaxItems parameter allows limiting the number of processed items
3. ItemSelector (Optional)
- Transforms each item before processing
- Uses JSONata expressions for data transformation
- Accesses the current item using
$states.context.Map.Item.Value - Particularly useful for formatting data before writing to DynamoDB
4. ItemBatcher (Optional)
- Groups items into batches for more efficient processing
- MaxItemsPerBatch: Controls how many items are included in each batch
- BatchInput: Adds additional context data to each batch
5. ResultWriter (Recommended for Large Outputs)
- Writes execution results to an S3 bucket3
- Prevents exceeding payload size limits
- Can configure output format (JSON/CSV) and transformation options
6. MaxConcurrency (Optional)
- Controls the number of child workflows executing in parallel
- Default is 10,000 if not specified
- Important for managing load on downstream services like DynamoDB
7. Failure Thresholds (Optional)
- ToleratedFailurePercentage/ToleratedFailurePercentagePath: Sets a percentage threshold for failed items
- ToleratedFailureCount/ToleratedFailureCountPath: Sets an absolute count threshold
- Allows the workflow to continue despite a certain number of failures
- Workflow fails with
States.ExceedToleratedFailureThresholderror when thresholds are exceeded
IAM Permissions Considerations
When implementing a Distributed Map state, your state machine requires specific IAM permissions:
- Permissions to invoke
StartExecutionon the child state machine - Permissions to describe executions of the child state machine
- Appropriate access to S3 buckets for reading data and writing results
- Any service-specific permissions needed by the child workflows4
This configuration provides a flexible and scalable approach to processing large datasets with Step Functions, allowing parallel processing of up to 10,000 concurrent executions.
Child Workflow Implementation: Detailed Walkthrough
The Inline Map state runs iterations within the parent workflow's context and is suitable for smaller datasets with limited concurrency requirements. In this example, the map state will process a JSON array. The JSON array represents a batch of order records.
.webp)
Inline Map State Configuration
The child workflow operates as the workhorse of our batch processing architecture, handling the actual data transformation and DynamoDB write operations. As shown in the workflow diagram, it employs an Inline Map state to process each batch of items efficiently within a single execution context.
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "PutItem",
"States": {
"PutItem": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:putItem",
"Arguments": {
"TableName": "{% $ddbTable %}",
"Item": "{% $states.input %}"
},
"End": true
}
}
},
"End": true,
"Items": "{% $states.input.Items %}"
}
Understanding the Child Workflow Structure
The workflow diagram illustrates the elegant simplicity of the child workflow:
- Initialization: The workflow begins with a Pass state that initializes variables needed for processing
- Map Processing: The Inline Map state iterates through each item in the batch
- DynamoDB Integration: Each item is written directly to DynamoDB using the PutItem API
Key Configuration Components
- Inline Map State Configuration
- ItemProcessor.ProcessorConfig.Mode: Set to "INLINE" to process iterations within the same execution context
- Items/ItemsPath:
- For JSONata expressions: Use
Itemsto specify the input array field ({% $states.input.Items %}) - For JSONPath expressions: Use
ItemsPathto define the path to the input array (e.g.,$.Items)
- For JSONata expressions: Use
- MaxConcurrency: Though not shown in the example, you can set this to control parallel processing (max 40 for Inline)
- ItemProcessor DefinitionThe ItemProcessor contains a nested workflow that:
- Starts with the state defined in
StartAt("PutItem") - Processes each item through the defined state machine logic
- Completes when reaching an
End: truestate
- Starts with the state defined in
- DynamoDB Integration
- Uses the built-in DynamoDB service integration (
arn:aws:states:::dynamodb:putItem) - Accepts dynamic parameters via JSONata expressions:
TableName: References a variable passed in the input ({% $ddbTable %})Item: Uses the current map item as the DynamoDB item ({% $states.input %})
- Uses the built-in DynamoDB service integration (
Express Workflows as Child Executors???
When implementing child workflows for distributed map processing, Express workflows are the preferred choice because they:
- Support shorter executions: Can run up to 5 minutes, ideal for batch processing tasks
- Cost efficiency: Are billed based on execution duration and memory usage rather than state transitions
- Simplicity: Support Inline Map states for processing batches of items within a single execution context
- Reduced overhead: Have lower latency for starting executions compared to Standard workflows
Implementation Considerations
When implementing child workflows, consider these best practices:
- Batch size optimization: Adjust the batch size in the parent workflow to balance processing efficiency with execution duration constraints
- Error handling: Implement retry logic for transient failures, especially with downstream services like DynamoDB
- Monitoring: Use CloudWatch metrics to track execution durations and adjust configurations as needed
- IAM permissions: Ensure the child workflow has appropriate permissions to interact with target services
This approach creates a scalable, efficient pattern for processing large datasets through the combination of a distributed map state in the parent workflow and inline map processing in child workflows.
Inline Map State Configuration
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "PutItem",
"States": {
"PutItem": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:putItem",
"Arguments": {
"TableName": "{% $ddbTable %}",
"Item": "{% $states.input %}"
},
"End": true
}
}
},
"End": true,
"Items": "{% $states.input.Items %}"
}
- old
Parent Workflow
This workflow reads data from a CSV file in an Amazon S3 bucket and divides it into batches for child workflows to store in DynamoDB. Using the DISTRIBUTED Map state processing mode, the parent workflow launches multiple child workflows. Each child workflow runs in its own execution context with separate, viewable execution logs.
- Start: The workflow begins when triggered.
- Read CSV File from S3:
- The map state reads a CSV file from the specified S3 bucket.
- The file location is defined using
<s3Prefix>/<s3Object>.
- Write Batch to DynamoDB Table:
- The CSV data is divided into batches for processing.
- A Step Functions task (
StartExecution) forwards these records to a child workflow for processing and DynamoDB storage. - The child workflow manages the batch writing process to DynamoDB, ensuring efficient data ingestion.
- Map Run Output Export Location:
- The map run can store results in an S3 bucket, specified as
<<<S3 Bucket>>>.
- The map run can store results in an S3 bucket, specified as
- End: The workflow concludes once all CSV records have been processed by the child workflow.
Distributed Map State Configuration
Use the Item Processor field to set the map state processing mode to Distributed and the child workflow type to Express.
In our example, we use the distributed map state in the parent workflow to launch child workflows that process a batch of records from the dataset.
We implement an Express step function as our child workflow. To set this up, you must specify the state machine ARN and the Input for the child state machine—the Input being an array of JSON objects.
The Step Functions resource that contains a Map State definition is referred to as the Parent Workflow.
The child workflow execution type will be an Express Step Functions state machine. Express workflows can run up to 5 minutes and are billed based on duration.
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "DISTRIBUTED",
"ExecutionType": "EXPRESS"
},
"StartAt": "Write a batch of items to DynamoDB table",
"States": {
"Write a batch of items to DynamoDB table": {
"Type": "Task",
"Resource": "arn:aws:states:::states:startExecution",
"Arguments": {
"StateMachineArn": "arn:aws:states:{{{AWS::Region}}}:{{{AWS::AccountId}}}:stateMachine:write-to-ddb",
"Input": "{% $states.input %}"
},
"End": true,
"Output": {
"childWfOutput": "{% $states.result %}"
}
}
}
}
Next, we will take a look at the map state input and output fields for Step Functions
Item Reader
The ItemReader specifies the data source location as an S3 bucket and key for the distributed map state.
"MaxConcurrency": 50,
"ItemReader": {
"Resource": "arn:aws:states:::s3:getObject",
"ReaderConfig": {
"InputType": "CSV",
"CSVHeaderLocation": "FIRST_ROW",
"CSVDelimiter": "COMMA",
"MaxItems": 10000
},
"Arguments": {
"Bucket": "<<s3Bucket>>",
"Key": "<<s3Prefix>>/<<s3Object>>"
}
}
MaxConcurrencydetermines how many child workflows can run simultaneously in parallel.- It supports other input types such as
JSON. Our example uses a CSV file. - In addition to S3, the map state can accept JSON array input from a previous state or task. The S3 bucket and key must be provided for S3 data sources.
💡The ItemReader property is omitted by default in the state machine definition when the input is a JSON array from a previous state.- CSV header location can be specified either in the state machine definition (
GIVEN) or within the source file (FIRST_ROW). Our example uses CSV data with headers in the first row. MaxItemslets you limit the number of records processed from the source dataset—particularly useful during testing.
Item Selector
The ItemSelector modifies each item before passing it to the child workflow. The JSONata expression $states.context.Map.Item.Value references the current JSON item or object.
The CSV data follows this schema:
{
"orderNumber": "ON123456",
"orderDate": "2025-02-25",
"orderStatus": "OPEN",
"lineItems": 2,
"totalPrice": "106.3"
}
You can access individual fields within the JSON item. For example, we combine the order number and order date to create a sort key for DynamoDB. We then store the entire record as a JSON object using DynamoDB's map type, formatting the resulting JSON according to DynamoDB's specifications.
"ItemSelector": {
"pk": {
"S": "{% 'TEST_CSV_LOAD' %}"
},
"sk": {
"S": "{% $states.context.Map.Item.Value.orderNumber & '-' & $states.context.Map.Item.Value.orderDate %}"
},
"data": {
"M": "{% $states.context.Map.Item.Value %}"
}
}
Item Batcher
This parameter specifies how many items to group into a batch before sending them to each child workflow execution.
The BatchInput property allows you to include additional fields with every batch.
"ItemBatcher": {
"MaxItemsPerBatch": 10,
"BatchInput": {
"ddbTable": "whatever"
}
}
Let's look at a sample input for the child workflow. The ddbTable property specifies the DynamoDB table name for data storage. This field comes from the BatchInput property and is included in the input.
The Items array holds the transformed records from the source dataset. When no additional fields are specified, the child workflow simply receives a JSON array of items as input.
{
"ddbTable": "whatever",
"Items": [
{
"pk": {
"S": "TEST_CSV_LOAD"
},
"sk": {
"S": "ON123456-2025-02-25"
},
"data": {
"M": {
"orderNumber": "ON123456",
"orderDate": "2025-02-25",
"orderStatus": "OPEN",
"lineItems": 2,
"totalPrice": "106.3"
}
}
},
{},
{},
...
]
}
Result Writer
To prevent exceeding the maximum payload size limit, we write each child workflow's execution results to S3 by specifying the bucket and location. The output is formatted as JSON.
This approach is particularly valuable when processing large volumes of data, as in our use case.
"ResultWriter": {
"Resource": "arn:aws:states:::s3:putObject",
"Arguments": {
"Bucket": "<<s3Bucket>>",
"Prefix": "<<s3Prefix>>/<<s3Object>>"
},
"WriterConfig": {
"OutputType": "JSON",
"Transformation": "COMPACT"
}
}
Child Workflow
We use Express Step Functions for our batch processor (child workflow). Express workflows are billed based on total duration and can run for up to 5 minutes. They support only the inline map state, which runs within the child workflow's context as it processes items in the batch.
The child workflow is an Express Step Function that accepts two inputs: a DynamoDB table name and a batch of items to store in that table.
When the Orchestrator's Map Run invokes each child workflow, it passes a JSON array as input. Using the INLINE processing mode, the Map state iterates through each array item and stores it in DynamoDB. This step function demonstrates a simple example of using Variables in Step Functions.
Using the Inline processing mode, the child workflow iterates through each array item and stores it in DynamoDB.
The Child Workflow state machine also demonstrates a simple example of using Variables in Step Functions.- Initialize Variables:
- The workflow starts with a
Passstate to set up variables and establish the processing context. - This ensures all necessary configurations are in place for record processing.
- In our example, we assign the DynamoDB table name to a variable.
- The workflow starts with a
- Map State:
- The
Mapstate processes the JSON payload using an INLINE map state, handling each batch item sequentially. - Each record flows through this state for processing.
- We define the
Item SourceasJSON Payload, specifying JSON-structured input data.
- The
- PutItem in DynamoDB:
- A
DynamoDB: PutItemtask writes each processed record to the specified DynamoDB table.
- A
- End:
- The workflow completes once all records are stored in DynamoDB.
Inline Map State Configuration
The following is the configuration for our Inline map state. Use the Item Processor to set the map state processing mode to Inline.
We call DynamoDB’s Put Item service, while providing the Dynamodb Table Name to store the data and the Item to be stored.
The Items field allows us to specify the input field that contains the JSON array.
"Map": {
"Type": "Map",
"ItemProcessor": {
"ProcessorConfig": {
"Mode": "INLINE"
},
"StartAt": "PutItem",
"States": {
"PutItem": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:putItem",
"Arguments": {
"TableName": "{% $ddbTable %}",
"Item": "{% $states.input %}"
},
"End": true,
"Output": {
"stateResult": "{% $states.result %}",
"isExecutionSuccess": "yeahhhhhhhhhhhh"
}
}
}
},
"End": true,
"Items": "{% $states.input.Items %}"
}
Error Handling
While we've focused on the map state, Step Functions also provides robust error handling capabilities essential for production-grade data processing:
- Configurable retry policies for transient failures
- Fallback states for graceful error handling
- Automatic state transition tracking
- Built-in error catch mechanisms
To implement error handling in your workflow:
- Identify potential failure points in your data processing pipeline
- Configure appropriate retry policies based on error types
- Implement fallback states for graceful degradation
- Set up monitoring and alerting for critical errors
For detailed guidance on implementing error handling in Step Functions, refer to the AWS documentation on error handling.
Conclusion
While Apache Spark and AWS Step Functions Distributed Map State both enable large-scale data processing, they represent fundamentally different paradigms. Spark is a cluster-based framework optimized for distributed data transformations and analytics, leveraging in-memory computation for high-performance workloads. In contrast, Distributed Map State offers a serverless orchestration model, ideal for executing parallel workflows across datasets without managing infrastructure. Depending on the problem at hand, one solution may be more suitable than the other—for example, Spark excels in complex transformations and iterative computations, while Distributed Map State is better suited for lightweight, scalable task orchestration across massive datasets stored in Amazon S3. Understanding these distinctions can help teams choose the approach that aligns best with their requirements and expertise.
In this walkthrough, we explored how to use Step Functions' distributed map state to process large amounts of data in S3, introduced variables in Step Functions, gained experience with JSONata, and worked with the Step Functions Workflow Studio—now available in VS Code!
The Distributed Map state in AWS Step Functions provides a scalable and efficient way to process large datasets. Its ability to spawn multiple child workflows, process data in parallel, and maintain detailed execution logs makes it perfect for ETL (Extract, Transform, Load) operations and data migrations.
Key advantages of this approach include:
- Scalable processing through parallel execution of child workflows
- Built-in error handling and retry mechanisms
- Flexible input processing with support for CSV and JSON formats
- Efficient batch processing capabilities
- Comprehensive logging and monitoring of execution status
By implementing this pattern, organizations can build robust, maintainable, and scalable data processing solutions while leveraging AWS services' serverless capabilities.



%20(1).svg)

.svg)